Depois de tanto pesquisar sobre essa questão de como abrir um arquivo grande em Delphi para seu processamento, decidi escrever sobre este tema, um tanto delicado por ser difícil chegar a uma conclusão satisfatória e que agradassem a gregos e troianos – pois um arquivo grande poderia gerar facilmente uma exceção do tipo “OutOfMemory” quanto travar a aplicação de forma incessantemente demorada – alternativas como file mapping, ler cada linha em readln ou carregar tudo em loadfromfile/loadfromstream utilizando stringlist´s podem não ser uma ideia tão interessante – vão demorar para processar e algumas vezes irão ocasionar o mesmo erro de falta de memória citado acima.
A ideia que venho mostrar aqui é simples mas funciona perfeitamente. Não é ideal para arquivos pequenos (onde a comparação com um dos modos tradicionais de abrir arquivos) pois o “tiro poderá sair pela culatra” – ficará mais lento do que deveria: essa interessante e eficiente técnica somente deverá ser aplicada a arquivos grandes – preferencialmente de 100 kB para cima.
O que tem que ser feito basicamente é o seguinte:
-
Obter o arquivo grande;
-
Dividir este arquivo em vários mini-arquivos;
-
Cada arquivo terá uma thread para sua leitura;
-
Ler cada mini-arquivo isoladamente da VCL;
-
Armazenar em cada instância de um objeto TMemo o resultado da leitura;
-
Acessar cada parte de um objeto TMemo através de um objeto TClientDataSet.
Basicamente o processo é este. Vamos embarcar nessa aventura ?
Primeiros passos com a leitura MultiThread
As primeiras coisas a serem notadas na construção do nosso aplicativo é que ele próprio é “consciente” na distribuição dos arquivos temporários e sua manipulação – sem desperdiçar nenhum byte ou ser lento neste processo – todos os cálculos da administração dos tamanhos de cada arquivo bem como o buffer redimensionado em tempo de execução serão gerenciados pelo nosso aplicativo de forma transparente para o usuário – eficiente e com componentes progressbar para que fique ciente da execução desta tarefa.
É claro que o bom-senso é fundamental para que o programa demonstre rapidez na sua resposta – um arquivo texto com mais de 500MB poderá levar até 6 minutos de espera – o que foi utilizado foi um de 500MB levando em média 3 minutos – “não podemos fazer milagre” – mas é muito útil para o gerenciamento dos lotes gerados e o retorno é bem melhor bem como a recuperação dos erros – tente a forma tradicional levar sempre uma exceção de “sem memória” e consequentemente o encerramento do aplicativo – o arquivo não será lido e o tempo que será gasto para lidar com uma solução intermediária de leitura será superior ao tempo de resposta da nossa solução aqui apresentada.
Foram experimentadas alternativas inviáveis, um tanto exploradas pela Web, mas que não trouxeram uma solução que chegasse perto a de que foi implementada aqui. Utilizar recursos de Memory Mapping Files, FileStreams, etc, podem ser bons para arquivos não tão grandes – eles vão “travar” sua aplicação porque a memória do Windows vão derrubá-los – assim como um dominó. Não gaste mais tempo contando com objetos do tipo TStringList, TList, etc; eles não vão pensar duas vezes e vão responder que não tem a memória que precisam – e vão deixar você na mão, infelizmente. O que poderá ser feito é o que foi dito inúmeras vezes acima – funciona em poucos minutos – o usuário acompanha o progresso do trabalho enquanto que o arquivo (que não queria ser lido de jeito nenhum pelo Windows) é finalmente carregado – em lotes – um por um – e sendo “printado” para a tela de sua aplicação – vemos agora que existe uma luz no fim do túnel.
Administração do Buffer
Para que o buffer seja preenchido e lido, algumas considerações são necessárias e são citadas abaixo:
-
O programa obtém o tamanho do arquivo em bytes (por exemplo, um arquivo com 2887 KB será gerado com 2955545 bytes pela nossa função de obter tamanhos de arquivos);
-
O programa gerará um “tamanho padrão” dos arquivos em lotes a serem gerados (baseando no mesmo exemplo, este arquivo terá o tamanho padrão de divisão dos seus arquivos em lotes de 295600 bytes, ou seja, 288,671875 KB cada um);
-
Baseado neste “tamanho padrão” o programa gerará os lotes necessários neste tamanho para cada um, até preencher todos eles com os dados do arquivo original;
-
O programa criará um objeto TFileStream para cada lote gerado;
-
Assim sendo, o programa criará uma thread para cada lote a fim de ler o conteúdo deles (poderão ser geradas várias threads de uma vez – prioridade normal);
-
O programa calculará o tamanho do buffer de leitura da thread com base no seguinte: 1024 (KB) vezes o tamanho do arquivo;
-
Cada thread criará um objeto TFileStream encarregado da leitura de cada lote corrente em que esta thread administra;
-
O buffer é preenchido com este objeto TFileStream;
-
É criado um objeto TMemo que irá receber o conteúdo deste buffer;
-
Este objeto TMemo será gerenciado internamente pelo programa, a fim de ser visualizado no momento apropriado, visto que vários deles poderão ser gerados (um por lote) – sendo que alguns métodos não serão utilizados a fim de agilizar a execução deste processo de criação (como o método clear, por exemplo);
-
Será criado um objeto TClientDataSet para o gerenciamento de todos os lotes, a fim de mostrá-los disponíveis em uma grid e serem selecionados e visualizados pelo usuário.
Segue abaixo o trecho do código-fonte responsável pela leitura do buffer, caracter a caracter, do tipo AnsiChar. Note que foi definido um “filtro” para esta leitura. Esta procedure se encontra na nossa thread de apoio.
procedure TFileReadThread.FileRead;
var
Stream: TFileStream;
i: integer;
Buffer: array of AnsiChar; //1024 (kB) x tamanho do arquivo ...
TempStr: string;
const Allowed = ['A' .. 'Z', 'a' .. 'z', '0' .. '9', '_', #13, #10, '-', '\', '"', '!', '@'
,'#', '$', '%', '¨', '*', '(', ')', '{', '}', '[', ']', '<', '>', '.', ':', ';', ',' , '?', '!', '/',
'+', '-', '´', '`', '=', '^', '~', '&', ' '];
begin
TempStr := '';
SetLength(Buffer, self.iFileSize + 1);
Stream := TFileStream.Create(self.strFileName ,fmOpenRead);
try
Stream.Read(Buffer[0], self.iFileSize + 1);
finally
Stream.Free;
end;
for i := Low(Buffer) to High(Buffer) do
if (Buffer[i] in Allowed) then
TempStr := TempStr + Buffer[i];
Form1.memo3.Lines.Add('Arquivo ' + Self.strFileName + ' lido com sucesso.');
Form1.CriaMemos(Self.Id, TempStr);
// Form1.strList.AddObject(TempStr, TObject(Self.Id));
end;
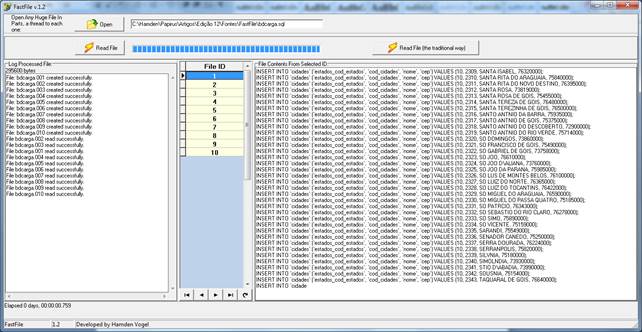
Figura 01 – Resultado final do processo de leitura em lotes.
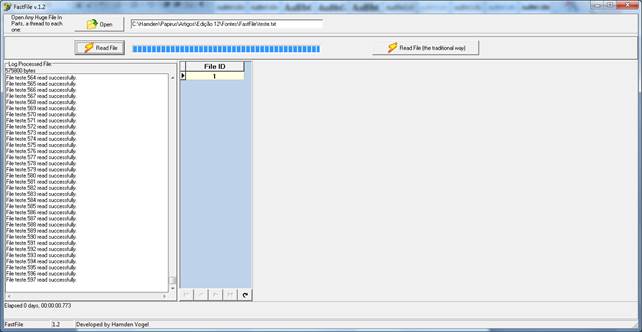
Figura 02 – O processo sendo lido em lotes.
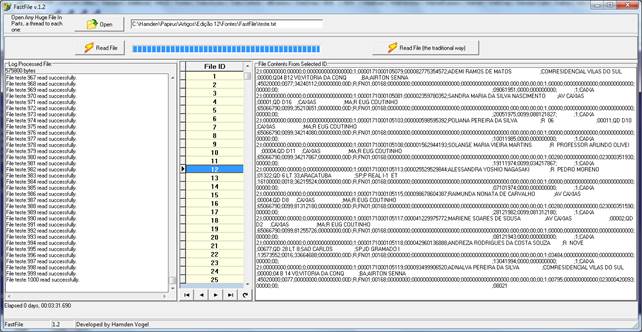
Figura 03 – Mais um exemplo de leitura em lotes – note que este arquivo processado em lotes tem 562 MB, sendo lido em 3 minutos. Foram criados 1000 lotes para sua visualização. Cada lote poderá ser processado da forma mais conveniente, em um loop ou em um evento próprio – por exemplo, para a leitura dos lotes “linha por linha” como em um readln.
Seguem abaixo trechos do código-fonte responsável para o fornecimento do tamanho padrão de cada lote:
function TfrmMain.NumberOfPartsToDivide(const filesize: integer): integer;
var
denominator: integer;
{ In fraction, the denominator will match the amount of exact parts where the file will be divided,
while the numerator is the file size.
Em fração, o denominador corresponderá a quantidade de partes exatas em que será dividido o arquivo,
enquanto que o numerador será o tamanho do arquivo. }
begin
case length(IntToStr(Round(filesize/1000))) of //convert to bytes
1: denominator := 4;
2: denominator := 8;
else
denominator := Round(Math.Power(10, length(IntToStr(filesize)) - Round(length(IntToStr(filesize)) / 2)));
end;
Result := Round(filesize/denominator) * 100;
end;
Segue abaixo a função responsável por criar os arquivos em lote e preenchê-los com base no tamanho padrão fornecido anteriormente:
procedure TfrmMain.FileSplit(const StrFilename: String);
var
StrmInput, StrmOutput : TFileStream;
FileNumber : Integer;
FileSize: integer;
SequentialFile: string;
begin
if (StrFilename = '') then Exit;
if not (FileExists(StrFilename)) then Exit;
tempFolder := Biblioteca.ExtractName(SysUtils.ExtractFileName(StrFilename));
if SysUtils.DirectoryExists(LocalDirectory + tempFolder) then SysUtils.RemoveDir(LocalDirectory + tempFolder);
SysUtils.CreateDir(LocalDirectory + tempFolder);
//FileSize := Round(Biblioteca.GetFileSize(StrFilename) / NumberOfParts);
FileSize := NumberOfPartsToDivide(Biblioteca.GetFileSize(StrFilename));
if not clOriginalFilePath.Locate('FILENAME', StrFilename, []) then
begin
clOriginalFilePath.Append;
clOriginalFilePath.FieldByName('FILENAME').AsString := StrFilename;
clOriginalFilePath.FieldByName('SIZEFILE').AsInteger := FileSize;
clOriginalFilePath.Post;
end
else
begin
clOriginalFilePath.Edit;
//clOriginalFilePath.FieldByName('FILENAME').AsString := ExtractFileName(ffile);
clOriginalFilePath.FieldByName('SIZEFILE').AsInteger := FileSize;
clOriginalFilePath.Post;
end;
lblFileSize.Caption := IntToStr(FileSize) + ' bytes';
FileNumber := 1;
iTotalFiles := 0;
ProgressBar.Position := 0;
memoLog.Clear;
StrmInput := TFileStream.Create(StrFilename,fmOpenRead or fmShareDenyNone);
try
while StrmInput.Position < StrmInput.Size do
begin
SequentialFile := ChangeFileExt((ExtractFilePath(StrFilename) +
IncludeTrailingPathDelimiter(tempFolder) + ExtractFileName(StrFilename)),'.'+Format('%.03d',[FileNumber]));
StrmOutput := TFileStream.Create(SequentialFile ,fmCreate);
try
if StrmInput.Size - StrmInput.Position < FileSize then
FileSize := StrmInput.Size - StrmInput.Position;
StrmOutput.CopyFrom(StrmInput,FileSize);
memoLog.Lines.Add('File: ' + ExtractFileName(SequentialFile) + ' created successfully.');
Application.ProcessMessages;
finally
StrmOutput.Free;
end;
Inc(FileNumber);
Inc(iTotalFiles);
ProgressBar.Position := ProgressBar.Position + 1;
end;
finally
StrmInput.Free;
end;
ProgressBar.Max := iTotalFiles;
end;
Aplicativo para processar em lotes passo-a-passo
Inicialmente, foi concebida a ideia de realizar o processamento passo-a-passo, isto é, em vez de o nosso aplicativo anterior (FastFile) executar tudo automaticamente, o usuário poderá acompanhar mais de perto de como a coisa toda funciona.
Gerando um passo por vez poderá ter a noção de como as funções de criação de lotes e a de leitura sincronizada (através de threads com a VCL) interagem entre si e resultam harmoniosamente no elo de criação e leitura das partes de um todo, “printando” o resultado em memo´s instanciados dinamicamente (sim, não há problema desde que se tenha memória – em um teste realizado aqui, foram criados 1000 memo´s sem problema algum).
Seguem abaixo duas funções: uma para obter o conteúdo de um TMemo e a outra para checkar o seu status (ativo/destruído/não existe):
function TForm1.GetMemo(const Id: integer): String;
begin
if MemoExists(Id) then
Result := TMemo(Self.FindComponent('memo_'+ IntToStr(Id))).Text
else
Result := '';
end;
procedure TForm1.CheckStatusMemo(const Id: integer);
var
garbage: TComponent;
begin
if MemoExists(Id) then
begin
garbage := Self.FindComponent('memo_'+ IntToStr(Id));
FreeAndNil(garbage);
end;
end;
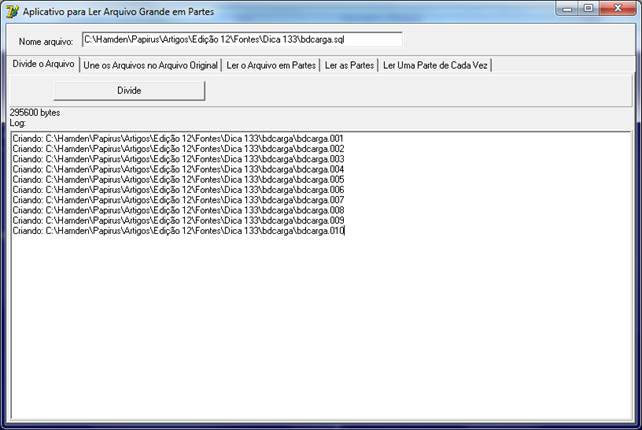
Figura 04 – aplicativo passo-a-passo – função para a divisão dos arquivos
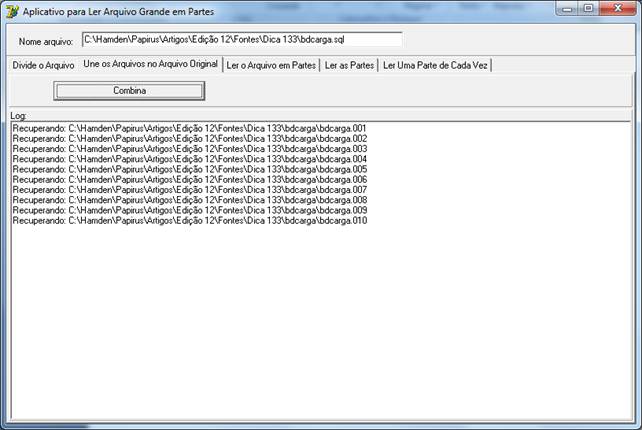
Figura 05 – aplicativo passo-a-passo – função para a união dos arquivos – note que esta função não é necessária para o processo de leitura em lotes discutido no nosso tema, mas útil para ilustrar o funcionamento inverso do nosso tema também.
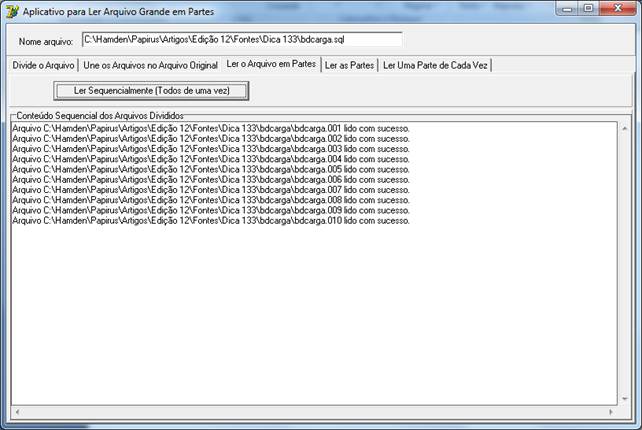
Figura 06 – aplicativo passo-a-passo – Memo contendo o registro das operações, como um Log.
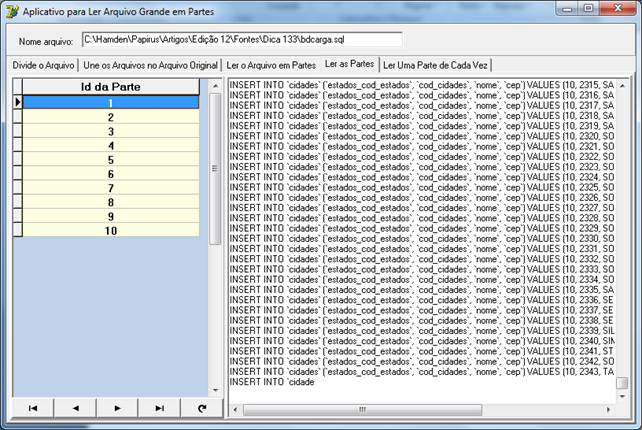
Figura 07 – aplicativo passo-a-passo – Leitura do arquivo em Lotes.
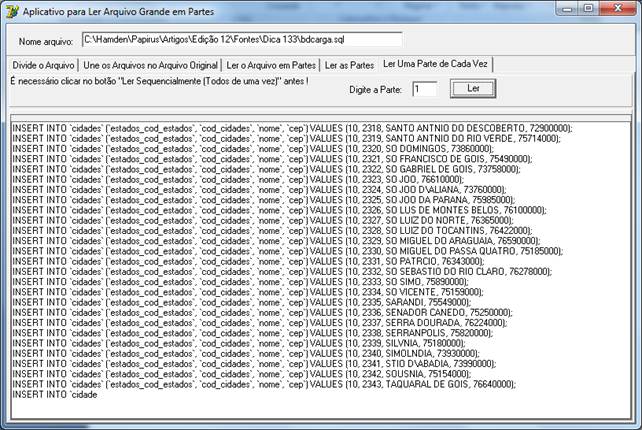
Figura 08 – aplicativo passo-a-passo – Leitura do arquivo em Lotes, com método de pesquisa.
Essa pesquisa por lote é interessante: o usuário digita o número do lote desejado e obtém o conteúdo deste lote. Assim, pode-se pesquisar por vez, a fim de exibir (neste caso, apenas um por vez) os dados contidos nele. Todos os caracteres são os preenchidos pelo buffer das threads através de um “filtro” (já citado acima).
Segue abaixo duas linhas do fonte responsáveis por esta função:
Memo4.Clear;
Memo4.Lines.Add(GetMemo(StrToIntDef(Edit1.Text, 1)));
Por fim, segue o código-fonte da thread chamada TFileReadThread:
{ TFileReadThread }
constructor TFileReadThread.Create(CreateSuspended: Boolean;
const myTempFileName: string; const myID, mySizeBuffer: integer);
begin
inherited Create(CreateSuspended);
self.strFileName := myTempFileName;
Self.Id := myID;
Self.iFileSize := mySizeBuffer;
Priority := tpNormal;
end;
destructor TFileReadThread.Destroy;
begin
inherited;
end;
procedure TFileReadThread.Execute;
begin
inherited;
FreeOnTerminate := True;
// if WaitForSingleObject(MutexHandle, INFINITE) = WAIT_OBJECT_0 then
// begin
Synchronize(FileRead);
// end;
// ReleaseMutex(MutexHandle);
end;
procedure TFileReadThread.FileRead;
var
Stream: TFileStream;
i: integer;
// Buffer: array[0..295600] of AnsiChar; //1024 (kB) x size of the file ...
Buffer: array of AnsiChar;
TempStr: string;
const Allowed = ['A' .. 'Z', 'a' .. 'z', '0' .. '9', '_', #13, #10, '-', '\', '"', '!', '@'
,'#', '$', '%', '¨', '*', '(', ')', '{', '}', '[', ']', '<', '>', '.', ':', ';', ',' , '?', '!', '/',
'+', '-', '´', '`', '=', '^', '~', '&', ' '];
begin
TempStr := '';
SetLength(Buffer, self.iFileSize + 1);
Stream := TFileStream.Create(self.strFileName ,fmOpenRead);
try
Stream.Read(Buffer[0], self.iFileSize + 1);
finally
Stream.Free;
end;
for i := Low(Buffer) to High(Buffer) do
if (Buffer[i] in Allowed) then
TempStr := TempStr + Buffer[i];
frmMain.memoLog.Lines.Add('File ' + ExtractFileName(Self.strFileName) + ' read successfully.');
frmMain.CreateMemos(Self.Id, TempStr);
frmMain.ProgressBar.Position := frmMain.ProgressBar.Position + 1;
// Form1.strList.AddObject(TempStr, TObject(Self.Id));
end;
Conclusão
Foi explicado neste artigo o funcionamento em tempo real a leitura de um arquivo grande em lotes, para isso dividindo cada um proporcionalmente em um tamanho padrão fornecido pela própria aplicação, e assim preenchendo dados nestes lotes e trazendo estes dados temporariamente para os componentes da VCL (através da instancialização de vários objetos TMemo´s, TClientDataSet´s e sincronizações com um TMemo para log e um TProgressBar para acompanhamento do processo).
Cada lote poderá ser criado e personalizado de forma livre para o implementador – a nomenclatura padrão é o nome do arquivo original mais o sequencial formatado em três casas decimais – exemplo ArquivoTal.001, ArquivoTal.002, etc;
Foram realizados testes apenas com arquivos binários/texto, processados em todas as etapas (divisão/união/leitura temporários) sempre com fluxo de dados do tipo TStream, aproveitando assim as funcionalidades de leitura por posição através do seu método CopyFrom.
O que quis trazer aqui é uma abordagem alternativa e eficiente para a leitura de arquivos pesados, como arquivos de carga, por exemplo, onde sempre sobrecarregam a entrada dos aplicativos devido ao seu tamanho – por mais que existam soluções para contornar essa leitura grande, muitas oneram o processador e vive de erros de falta de memória e com tempo demasiado para o processamento linha a linha – imagina uma linha para cada insert em um banco de dados de um arquivo de carga – sendo muito grande o Delphi nem vai iniciar a função – vai abortar com erros já citados de Exception “OutOfMemory”.
Portanto, com este aplicativo os arquivos grandes SEMPRE serão lidos, desde que o Windows apresente memória para tal. Não é recomendável memória com até 2 GB de RAM; sempre mais do que isso a partir de 3. Foi testado com 3 GB com resultados satisfatórios. A leitura sempre funcionará e nunca deixará o usuário “na mão”. Uma última e óbvia observação é a permissão de espaço em disco e capacidade do mesmo, para permitir a leitura/escrita e a capacidade de armazenamento dos lotes dos arquivos, respectivamente.
Essa é uma maneira multithread para agilizar a leitura dos lotes de um arquivo em particular, dividindo uniformemente em tamanho seus respectivos lotes e consumindo seus dados para dentro do programa em si, trazendo uma forma eficiente de ler os dados de forma sequência, ordenada e prática. Bons estudos e bons projetos com este artigo ! Seguem os fontes dos projetos baseados neste nosso tema em anexo. Até o próximo artigo !
|
